
Cet article se base sur un support de présentation du Data Marketing donnée à plusieurs occasions depuis septembre 2019 par Caroline GOUBAUD, fondatrice de Polydata.
lire la partie 1 : Introduction au data marketing – définitions
Adéquation du besoin et de l’outil
Avant de commencer un projet Data Marketing, il faut donc avoir identifié son ou ses besoins et sa maturité Data : 2 entrées qui permettront de dessiner le(s) projet(s) data marketing prioritaire(s) en fonction de 3 critères : faisabilité, rentabilité et délai.
La data se travaille à plusieurs niveaux, fonction de la maturité de l’entreprise sur ses besoins
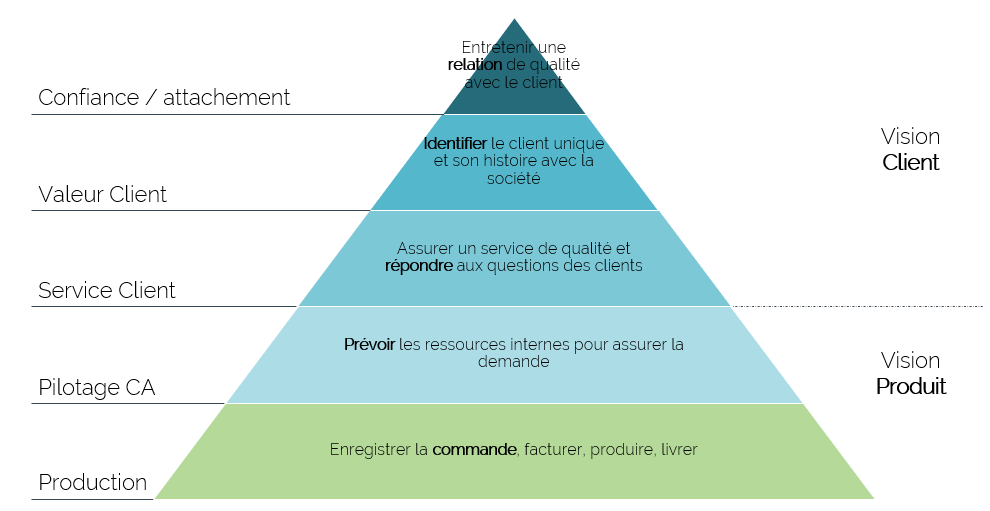
Répondre à une question avec la data nécessite de savoir se situer sur l’échelle de connaissance produit et client
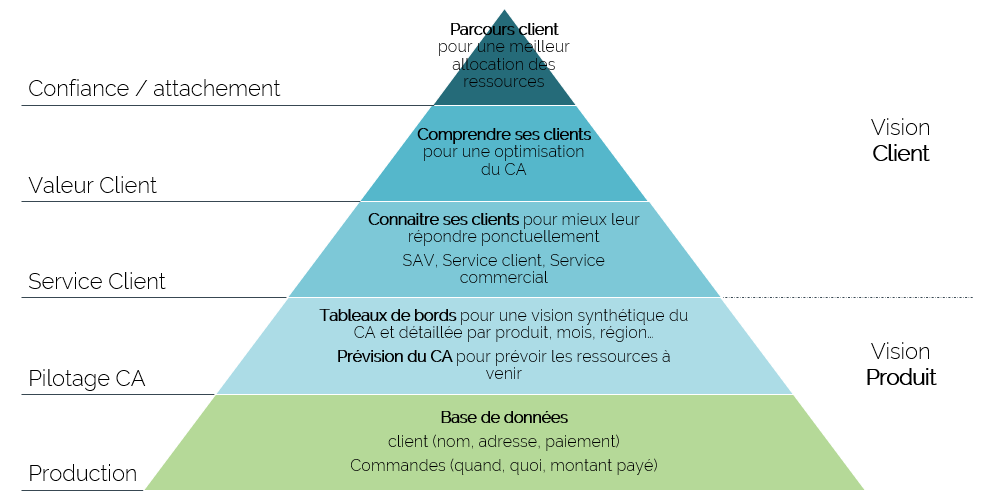
Pouvez-vous vous situer sur ces 2 pyramides ? Quel est votre état aujourd’hui ? et celui souhaité ? Le ressenti ? le réel ?
Pour faire cet « audit » il est nécessaire de prendre du temps et de se poser les bonnes questions.
Le projet Data Marketing
L’environnement et l’interprétation est au cœur de la pratique.
Sans un travail collaboratif étroit avec l’émetteur du besoin (donneur d’ordre), le résultat ne pourra être pertinent.
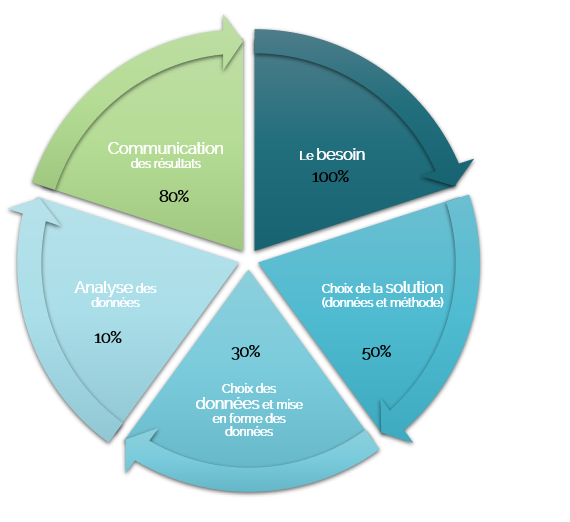
détail de chacune des 5 parties ci-dessous
L’expression du besoin se fait avec un concours à 100% de l’expert métier, le data scientist pourra ensuite prendre la main sur les étapes plus techniques mais toujours avec des allers et retours fréquents pour valider la pertinence des résultats ou méthodes choisies.
Le choix de la méthode pourrait être exclusivement confiée au data scientist. Mais si cette méthode est trop complexe comment l’entreprise peut-elle être autonome et la mettre à jour ?
Il faut parfois accepter de « dégrader » le résultat pour assurer que le l’analyse sera comprise et intégrée par l’entreprise. Une méthode simple et compréhensible facilite son usage, sa compréhension par les équipes et donc son impact.
Le bon sens est le meilleur guide.
Une segmentation peut être extrêmement pertinente et robuste en utilisant des méthodes combinées de data mining (machine learning). Celle-ci sera complexe à expliquer et à entretenir.
Si une segmentation client a été construite pour automatiser des prises de paroles propres à chaque segment, elle doit être mise à jour régulièrement.
Comment l’entreprise peut-elle automatiser la mise à jour de la segmentation client sans faire appel au data scientist régulièrement ou investir dans des solutions coûteuses si la solution est trop complexe ?
Il est alors parfois conseillé de démarrer par une segmentation « à priori », basée sur l’observation et l’expertise métier, simple, comme un RFM ce qui permet d’avoir des règles binaires à implémenter dans la base de données et simplifier la prise en main de celle-ci autant techniquement qu’intellectuellement.
Les données disponibles sont toujours propres à une entreprise, avec ses règles de gestions et évènements marquants. Impossible pour le data scientist de prendre en main une base de données sans des explications et du contexte.
Une base de données peut sembler propre mais elle demander un travail très important de nettoyage. Une donnée peut être disponible car existante mais non exploitable.
Exemple : Le client ayant passé une commande existe dans la BDD, mais celui-ci est présent plusieurs fois avec un nom ou une adresse différente, il faut alors « dédupliquer », en d’autre termes associer à une personne physique unique un identifiant unique qui sera associé à toutes ses actions (commandes, appel SAV, email reçu…) et ainsi obtenir la vision client 360°.
Il est souvent admis qu’une même analyse faite par deux data scientist différents ne donnera pas le même résultat. L’interprétation des résultats d’une analyse de données dépend du contexte de l’entreprise, de son histoire aussi bien commerciale que d’hébergement technique.
Un résultat peut sembler très satisfaisant pour le data scientist mais sans aucun intérêt pour l’entreprise : identifier que les 2 produits sont souvent achetés par un même client peut sembler être une trouvaille intéressante et à proposer à l’entreprise pour accroitre la valeur du client via le cross-selling. On proposera au client qui a acheté le produit A de promouvoir le produit B.
Mais après discussion, il est fort probable que ce pack de produit A&B, ait en fait été poussé par la force commerciale et que sa performance soit artificielle (stock trop important à réduire sur le produit B et donc poussé avec le produit A par exemple).
La communication des résultats est également primordiale, une analyse peut être extrêmement pertinente mais mal présentée ou sous un angle trop théorique ou encore trop jargonneux, celle-ci n’aura aucune utilité.
Partager les résultats de façon digeste & ludique, en lien avec la connaissance déjà acquise par l’expertise métier est central. Sans cela difficile de s’approprier cette nouvelle connaissance et de l’utiliser opérationnellement.
L’usage d’infographie, data visualisation sont fortement recommandées. L’aspect « ludique » et concret du livrable permet une meilleure diffusion et appropriation.
6 cas pratiques sont disponibles et peuvent être présentés à la demande (prévoir 1h de présentation pour l’ensemble, comprenant les parties 1 & 2)
Pour échanger : contact@poly-data.com